JungleDisk is another great entrant in the online backup business. Unlike Mozy, our favorite for Macs and PCs, JungleDisk also runs on Linux. And, since version 1.30a, it ships a command-line version.
Which means you can give your Linux servers reliable online backup — stored on Amazon’s S3.
These instructions cover version 1.50 — which has a different config file and a number of settings than previous versions. If you’re still using an older version, see the instructions for version 1.30 or 1.40 that we published a while back.
Meanwhile, let’s get down to business with version 1.50. Our server install has three parts:
- JungleDisk command line program, which makes S3 look like a WebDav server
- Fuse, which makes WebDav look like a regular Linux filesystem
- rsync, the standard Linux power copy program
You’ve got rsync, and the other two aren’t much harder to install.
1. Install Fuse
- Install Fuse. On Ubuntu Dapper this is easy once you enable the Universe repository. Later versions of Ubuntu have fuse-utils in the regular repositories.
sudo apt-get install fuse-utils sudo modprobe fuse - To keep JungleDisk happy, we’ll load the fuse kernel module automatically on boot.
sudo echo “fuse” >> /etc/modules
2. Install JungleDisk
- Download JungleDisk, and untar it. Since version 1.30a, the Linux package comes with both GUI and command-line versions.
junglediskis the command-line version we’ll use herejunglediskmonitoris the GUI version. This version makes it easy to sign up for S3, and it writes the config file for you automatically — but you’ve got to have X11 installed to run it :(.
- Sign up for an Amazon S3 account.
junglediskmonitorcan help you do this — if you’ve got X-windows installed. Thejunglediskmonitoralso creates a settings file. - Or if you install JungleDisk on a Mac or Windows PC you can copy the config from that install. (On a Mac, the config can be found here: ~/Library/Preferences/jungledisk-settings.ini)
- You could also use a different machine to run the USB-key version of JungleDisk, which lets you run the graphical setup on a Mac or PC and writes the settings back to the USB drive.
- Or you can make your own
~/.jungledisk/jungledisk-settings.ini. You’ll need to put your Amazon S3 access and secret keys and your username in place of the*<removed>*text below:
1 LoginUsername= 2 LoginPassword= 3 AccessKeyID=<removed> 4 SecretKey=<removed> 5 Bucket=default 6 CacheDirectory=/tmp/.cache/ 7 ListenPort=2667 8 CacheCheckInterval=120 9 AsyncOperations=1 10 Encrypt=0 11 ProxyServer= 12 EncryptionKey= 13 DecryptionKeys= 14 MaxCacheSize=50 15 MapDrive=J 16 UseSSL=1 17 RetryCount=3 18 FastCopy=1 19 WebAccess=0 20 LogDuration=0 21 ArchiveFlag=5 22 ArchiveDuration=60 23 MaxArchiveSize=100 24 PasswordPrompt=0 25 UploadResume=0 26 DeltaUpdates=0 27 PlusFallback=1 28 LargeWindows=0 29 License=
You can download a sample config file without the line numbers. A couple of lines will need editing to fit your circumstances.
Lines 3 and 4 are your Amazon S3 credentials. Copy and paste them from Amazon’s website. (Click the button labled “Your Web Services Account”, then choose “AWS Access Identifiers” to see these.)
Line 6: The directory where JungleDisk will write to while its processing. This needs to exist and be writable by the user who will run jungledisk.
Lines 1, 2 and 29 can be left blank (as they are here) for your 30-day trial of JungleDisk. Once you buy the software, however, you’ll want to fill them in. Lines 1 and 2 are the email address and password you used to make your JungleDisk purchase.
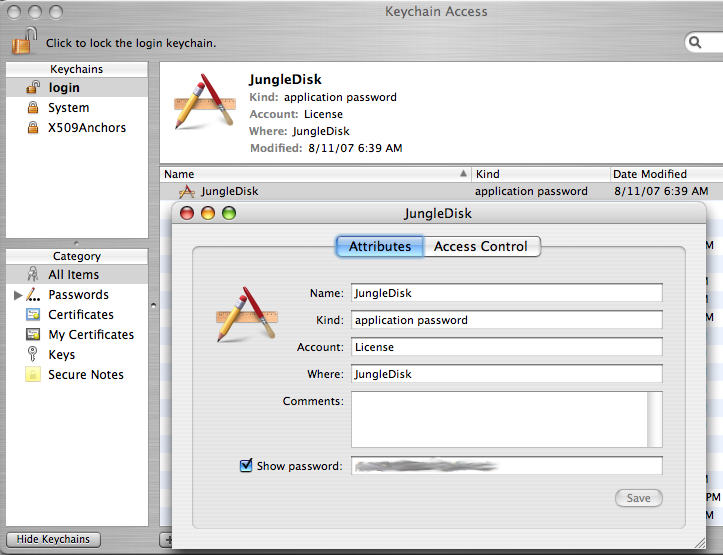
Line 29 is a license code generated by junglediskmonitor. I’m not aware of a way to produce this in the command-line client. The Mac OS X version of JungleDisk keeps the license in the keychain, where Keychain Access can show it. If anybody knows where to find this in Windows, please let us know in the comments.
{kind=link}
3. Actually Try it Out
Time to try it all out.
- Get ready to mount the jungledisk drive (first time)
sudo mkdir /mnt/s3
- Start jungledisk (/mnt/s3 is the mount point you just created)
./jungledisk/jungledisk /mnt/s3
- Actually copy something over to S3
echo “Here’s a file to try” > atestfile.txt sudo cp atestfile.txt /mnt/s3
4. Rsync Backups
If you don’t love rsync yet, you’re gonna. Can you say “Differential Copy algorithm”? Rsync only copies the changed stuff. And that’s what makes over-the-net backups workable.
Here’s how to back up the whole enchilada (or at least all of your server’s /home directories).
rsync -a --inplace --bwlimit=50 /home /mnt/s3
Notice that the rsync command adds a bandwidth limit (—bwlimit=50) to the inplace flags that JungleDisk recommends. Without this, you may find that jungledisk opens more files than the kernel will allow (at least in Ubuntu).
5. Automated Backups
And here’s the shell script we use to actually do the backup. Line 5 here shows that we’ve got one more choice here — when to start jungledisk. It could be done in line 5 here, but because it’s a background process we want to leave running, we could start it on bootup by adding the jungledisk command to the end of /etc/rc.local.
/usr/local/bin/backup-jd
1 #!/bin/sh 2 ### Backs up office data to Jungledisk using rsync 3 LOGFILE=/var/log/backup-jd.log 4 ## Start in rc.local or here 5 /usr/local/bin/jungledisk /mnt/s3 6 echo "`date +"%F %R"`: Start backup-jd" >> $LOGFILE 7 rsync -a --inplace --bwlimit=50 /home /mnt/s3 8 echo "`date +"%F %R"`: Finish backup-jd" >> $LOGFILE
Updates & Revisions
8/14/07: Originally published.
8/19/07: Add line numbers and a better explanation of the JungleDisk config file, plus a version for download.
4/18/08: Updated for JungleDisk version 1.50. The original post is here for anyone still using JungleDisk 1.30 or 1.40.
1 response
-
22 Sep 2007 02:53:39 PMMatt responded:
Thanks, great post. Now have automated backups running on my homeserver, plus a network drive I can access from the office too!